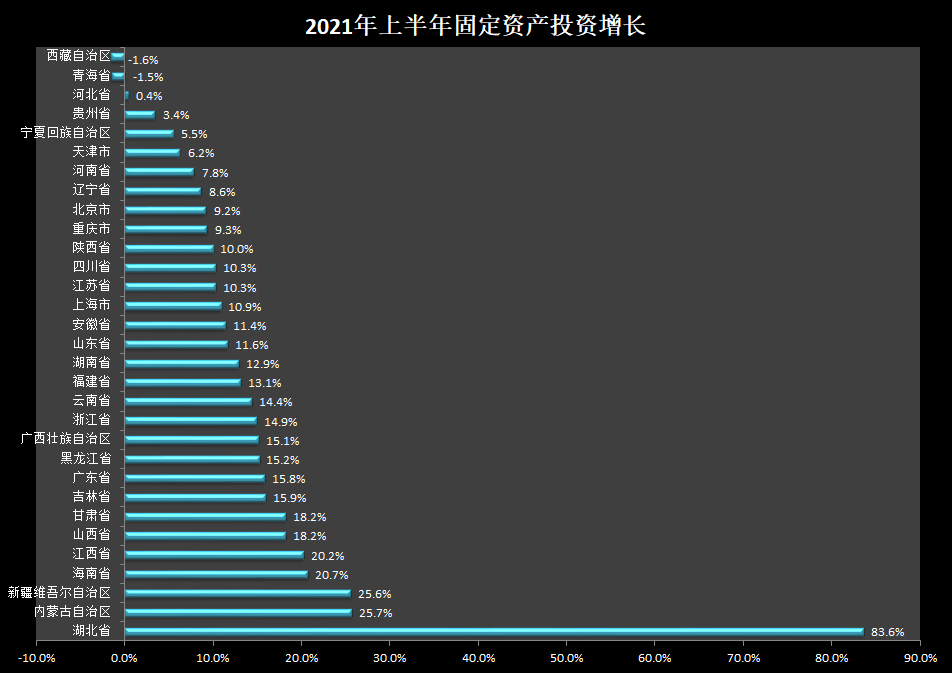
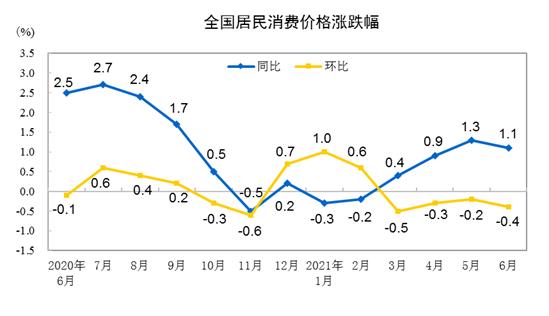
英伟达:已成功训练出世界上最大的语言模型
英伟达今日宣布,已经成功训练出世界上最大的语言模型。该模型是这家GPU制造商针对一系列会话式AI研发的最新版本。
为了实现这一突破,英伟达利用模型并行性,将神经网络分解成各个部分,并采用了由于过大而无法容纳在单个GPU内存中的模型创建技术。该模型使用了83亿个参数,比BERT大24倍,比OpenAI的GPT-2大5倍。除此之外,英伟达还宣布了BERT(Bidirectional Encoder Representations,双向编码器表示)的最快训练和推理次数。BERT是一种流行的模型,最初于2018年由谷歌开源,是当时最先进的模型。
英伟达能够利用优化的PyTorch软件和含超过1000个GPU的超级计算机DGX-SuperPOD训练BERT-Large。这些GPU训练BERT的耗时小于53分钟。“如果没有这种技术,训练其中任何一种大型语言模型都可能耗费数周时间,”英伟达应用深度学习副总裁Bryan Catarazano在与记者和分析师的对话中表示。
英伟达还表示其已实现了最快的BERT推理时间。基于Tesla T4 GPU和针对数据中心推理优化的TensorRT 5.1运行时,推理时间已降至2.2毫秒。Catarazano表示,当CPU运行时,BERT推理最多需要40毫秒,而目前,大量会话式AI的应用使这一过程缩短到10毫秒。不仅如此,GPU也为微软旗下的必应创造了收益,英伟达硬件的应用使必应的延迟时间缩短了一半。
当前推出的任何一项新技术都旨在强调该公司GPU在语言理解性能方面的提升。为了帮助AI从业者和研究人员探索并创建大型语言模型、加速GPU的推广或推理,上述每项新技术的代码都已开源。除了单词正确率的急速上升之外,减少延迟一直是各大流行AI助手被采用的主要因素,如亚马逊的Alexa、谷歌的Google Assistat和百度旗下的度秘(Duer)等。
少延迟甚至无延迟的信息交换使机器与人的对话像人与人之间的对话那样,即刻就能得到回应。与今年微软Cortana、亚马逊Alexa和Google Assistant推出的多轮对话功能相同,与AI助手进行实时沟通可以让互动感觉更自然、无障碍。
会话时AI系统最新的技术发展,大致上围绕着谷歌2017年Transformer语言模型和2018年BERT模型的更新。自此,以BERT为基础的三款模型:微软的MT-DNN、谷歌的XLNet和百度的ERNIE,均超越了BERT模型。今年7月份,Facebook推出了一款基于BERT的模型——RoBERTa。目前,RoBERTa在GLUE基准测试排行榜上位列第一,在9种语言任务中排名第4。这些模型在GLUE任务数据集上的排名均优于人类标准。